Hey there, curious learner! Have you ever wondered what bootstrapping is in the exciting world of machine learning? Well, get ready to dive into this fascinating concept that plays a crucial role in training models and making accurate predictions. Bootstrapping, in the context of machine learning, is a powerful technique that involves sampling data from a given dataset to create multiple subsets, also known as bootstrap samples. These samples are then used to train multiple models, enabling us to gain insights into the stability and variability of our predictions.
Now, you might be wondering how this process actually works. Picture this: imagine you have a dataset with a hundred observations. With bootstrapping, you randomly select a subset of, say, 70 observations from this dataset and create a bootstrap sample. The remaining 30 observations are left out, forming the out-of-bag (OOB) sample. You repeat this process multiple times, each time creating a new bootstrap sample and its corresponding OOB sample. These samples are then used to train different models, and the predictions from each model are combined to make accurate and robust predictions.
Bootstrapping is like throwing a party where each guest brings a unique perspective, and together, they form a diverse and insightful crowd. By training multiple models on bootstrap samples, we can analyze the OOB predictions, assess the stability of our models, and even estimate the uncertainty associated with our predictions. It’s a powerful technique that allows machine learning algorithms to make informed decisions and tackle complex problems with finesse. So, buckle up and get ready to explore the world of bootstrapping in machine learning!
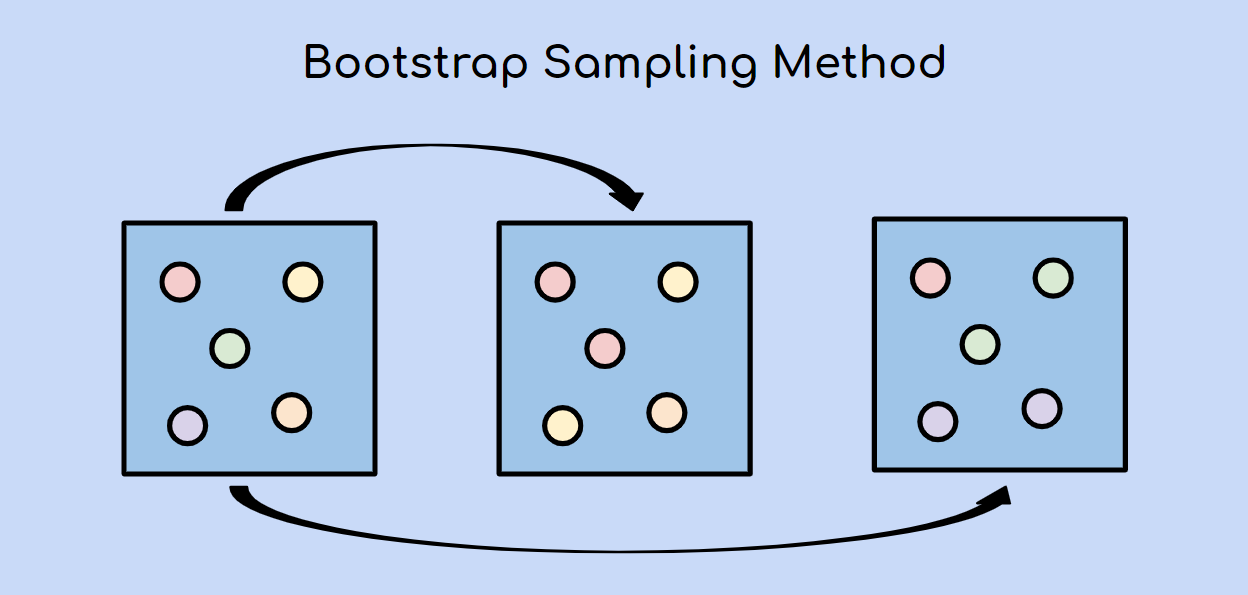
Understanding Bootstrapping in Machine Learning
Bootstrapping is a powerful technique in machine learning that involves creating multiple training datasets by randomly sampling the original dataset with replacement. This technique allows us to generate different variations of the training data, which can then be used to train multiple models. These models are then aggregated to make predictions, resulting in a more robust and accurate final model.
The Concept of Bootstrapping
Bootstrapping in machine learning is inspired by the statistical resampling technique called the bootstrap. The basic idea is to create multiple datasets by sampling the original dataset with replacement. Each bootstrap sample is the same size as the original dataset but may contain duplicate instances and miss some original instances.
The reason behind this technique is to introduce variation in the training process. By training models on different bootstrap samples, we can capture different aspects of the data and reduce the impact of outliers or noise. This helps to create a more stable and reliable model that generalizes well to unseen data.
Bootstrapping Process
The process of bootstrapping in machine learning involves the following steps:
1. Randomly sample instances from the original dataset with replacement to create a bootstrap sample.
2. Train a model on each bootstrap sample.
3. Aggregate the predictions from each model to make a final prediction.
4. Evaluate the performance of the final model on a separate validation set.
By repeating this process multiple times, we can create an ensemble of models that collectively make predictions. This ensemble approach helps to improve the accuracy and robustness of the final model.
Benefits of Bootstrapping
Bootstrapping offers several benefits in machine learning:
1. Robustness: By training models on different bootstrap samples, bootstrapping reduces the impact of outliers and noise in the data, resulting in a more robust model.
2. Accuracy: Aggregating the predictions from multiple models helps to reduce overfitting and improve the overall accuracy of the final model.
3. Generalization: Bootstrapping allows the model to capture different aspects of the data, leading to better generalization and performance on unseen data.
4. Model Selection: By training multiple models, bootstrapping allows for model selection based on their individual performance. This helps to choose the best model for making predictions.
5. Confidence Intervals: Bootstrapping can also be used to estimate confidence intervals for model performance metrics, providing a measure of uncertainty in the predictions.
Bootstrapping vs. Cross-Validation
While bootstrapping and cross-validation share similarities, they are distinct techniques. Cross-validation involves partitioning the dataset into multiple subsets called folds and training models on different combinations of these folds. This helps to estimate the model’s performance on unseen data.
On the other hand, bootstrapping focuses on resampling the dataset to create multiple training datasets. The models are then trained on these different datasets and aggregated to make predictions. Bootstrapping is particularly useful when the dataset is small or when we want to improve the robustness and accuracy of the model.
Both techniques have their advantages and are valuable tools in machine learning. The choice between bootstrapping and cross-validation depends on the specific problem and the goals of the analysis.
Benefits of Bootstrapping in Machine Learning
Bootstrapping in machine learning offers several benefits over traditional cross-validation techniques:
1. Flexibility: Bootstrapping allows for greater flexibility in training and evaluating models. It is not limited to a fixed number of folds and can generate an unlimited number of bootstrap samples.
2. Robustness: Bootstrapping is more robust to outliers and noise in the data compared to cross-validation. By creating multiple training datasets, bootstrapping reduces the impact of individual instances on the final model’s performance.
3. Accuracy: The aggregation of predictions from multiple models helps to improve the overall accuracy of the final model. This ensemble approach minimizes overfitting and captures different aspects of the data.
4. Model Selection: Bootstrapping provides an opportunity to evaluate and compare multiple models trained on different bootstrap samples. This helps in selecting the best model for making predictions.
In summary, bootstrapping is a valuable technique in machine learning that allows for the creation of multiple training datasets. By training models on these different datasets and aggregating their predictions, bootstrapping helps to improve the accuracy, robustness, and generalization of the final model. It is a powerful tool for machine learning practitioners seeking to build reliable and accurate models.
Key Takeaways: What is Bootstrapping in Machine Learning?
- Bootstrapping is a technique in machine learning where we create multiple datasets by resampling from the original dataset.
- Each dataset is created by randomly selecting samples from the original dataset with replacement.
- These bootstrapped datasets are used to train multiple models, and predictions are made by averaging the results from these models.
- Bootstrapping helps in estimating the uncertainty and variability of the model’s predictions.
- It is a powerful method for improving the performance and robustness of machine learning models.
Frequently Asked Questions
Question 1: How is bootstrapping used in machine learning?
Bootstrapping is a technique used in machine learning to estimate the accuracy or variability of a statistical learning method. It involves creating multiple subsets of the original dataset through random sampling with replacement. These subsets, known as bootstrap samples, are used to train multiple models. By aggregating the results from these models, we can obtain more robust and reliable predictions.
Bootstrapping is particularly useful when the dataset is limited or when the algorithm is prone to overfitting. It helps in reducing the bias and variance of the model, resulting in better generalization and improved performance on unseen data.
Question 2: What is the concept of resampling in bootstrapping?
Resampling is a fundamental concept in bootstrapping. It involves randomly selecting observations from the original dataset with replacement to create bootstrap samples. The size of each bootstrap sample is usually the same as the original dataset, but it can also be smaller or larger depending on the specific application.
By resampling the data, we are able to create multiple training sets that are similar to the original dataset. This allows us to estimate the variability and uncertainty associated with the model’s predictions. Resampling also helps in capturing the underlying patterns and relationships in the data, leading to more accurate and reliable models.
Question 3: How does bootstrapping help in assessing model performance?
Bootstrapping provides a powerful tool for assessing the performance of machine learning models. By creating multiple bootstrap samples and training multiple models, we can obtain a distribution of performance metrics such as accuracy, precision, recall, and F1 score.
This distribution allows us to estimate the variability and uncertainty in the model’s predictions. It provides insights into the stability and robustness of the model, helping us make informed decisions about its suitability for a given task. Additionally, bootstrapping can also be used to test the statistical significance of the model’s performance by comparing it to a null hypothesis.
Question 4: How does bootstrapping handle imbalanced datasets?
Imbalanced datasets, where the number of instances in different classes is significantly different, can pose challenges for machine learning algorithms. Bootstrapping can be a useful technique in handling such datasets.
By creating bootstrap samples, we can balance the distribution of classes in each sample. This helps in preventing the model from being biased towards the majority class and improves its ability to learn from the minority class. Additionally, bootstrapping can be combined with other techniques such as oversampling or undersampling to further address the class imbalance issue.
Question 5: What are the limitations of bootstrapping in machine learning?
While bootstrapping is a powerful technique, it has its limitations in machine learning. One limitation is that it assumes the bootstrap samples are independent and identically distributed, which may not always hold true in practice.
Another limitation is the potential for overfitting. If the original dataset is small or if the algorithm is complex, there is a risk of overfitting the bootstrap samples and obtaining overly optimistic performance estimates. This can lead to poor generalization on unseen data.
Despite these limitations, bootstrapping remains a valuable tool in machine learning for estimating model performance, handling imbalanced datasets, and improving the robustness of predictions.
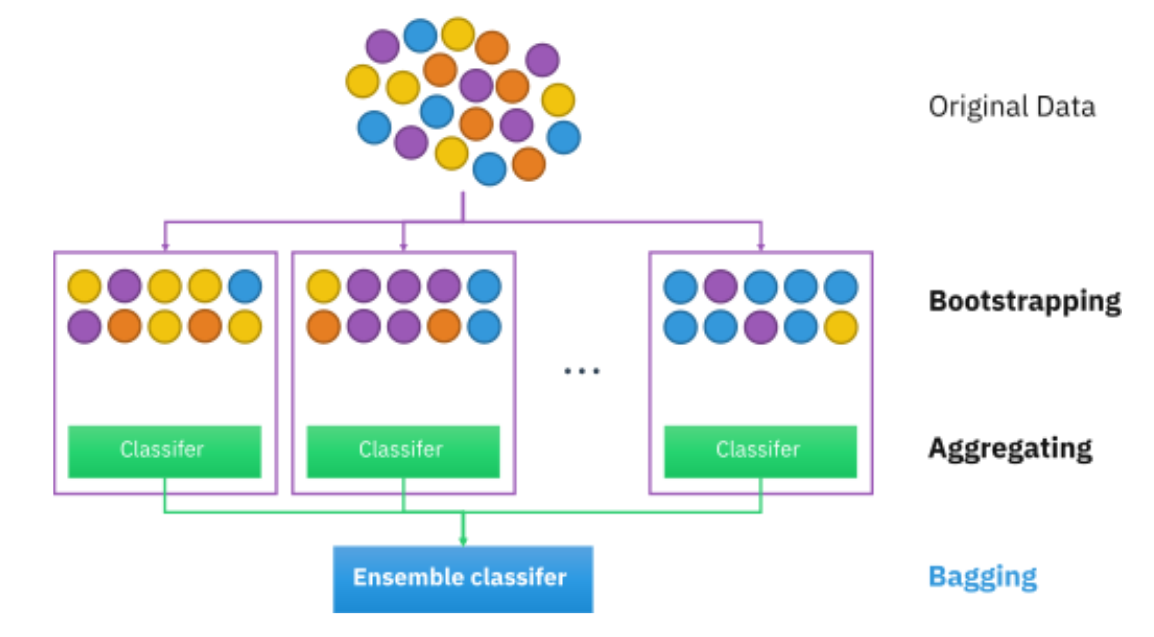
Final Summary: Understanding Bootstrapping in Machine Learning
After diving into the concept of bootstrapping in machine learning, we can conclude that it is an incredibly powerful technique that plays a crucial role in the development of accurate and robust models. Bootstrapping allows us to generate multiple training sets by resampling the original data, enabling us to gain a deeper understanding of the underlying patterns and variability within the dataset. This approach helps to improve the generalization of machine learning models by reducing overfitting and increasing stability.
By employing bootstrapping, machine learning practitioners can create ensemble models that aggregate the predictions of multiple models trained on different subsets of the data. This ensemble approach enhances the accuracy and reliability of the final predictions, making it a popular method in various fields, including finance, healthcare, and natural language processing. Moreover, bootstrapping is an essential tool for estimating the uncertainty associated with model predictions, allowing us to quantify the confidence intervals and make more informed decisions based on the level of uncertainty.
In conclusion, bootstrapping in machine learning empowers us to build robust and accurate models by resampling the data and creating ensemble models. This technique not only improves generalization and stability but also provides a means to estimate uncertainty. By incorporating bootstrapping into our machine learning workflows, we can elevate the performance and reliability of our models, opening doors to new possibilities and insights in the world of data-driven decision making. So, let’s embrace bootstrapping and unlock the true potential of machine learning.








